前一天介紹了selenium與requests的差別,提到了selenium該如何取得網站的資訊,那今天來介紹其他selenium的函式吧。
來介紹一個非常好用的模塊"WebDriverWait"
在爬某些網站時,會先遇到網頁已經讀取完畢了,但網頁資訊還沒有出來
例如我們想要取得台水的停水資訊,以台中市為舉例,我們想要取得第一筆的停水資訊,如下圖

這時執行程式
driver.get('https://www.water.gov.tw/wateroff/city/%E8%87%BA%E4%B8%AD%E5%B8%82/index.html')
print(driver.find_element(By.XPATH, "/html/body/main/div/div[2]/div[1]/div/div[1]/a"))
結果顯示no such element: Unable to locate element: {"method":"xpath","selector":"/html/body/main/div/div[2]/div[1]/div/div[1]/a"}
的錯誤
這時我們必須使用可以等待網頁資訊出現的手法,或許會想 time.sleep() 可以讓程式不執行一段時間,但這是不切實際的,要考慮每個人的網路狀況不同,以及請求的資料不一樣做考慮,這時可以使用一個"可以等待直到讀取到網頁元素出現"的函式。
以下是修改後的程式碼
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://www.water.gov.tw/wateroff/city/%E8%87%BA%E4%B8%AD%E5%B8%82/index.html')
print(WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, "/html/body/main/div/div[2]/div[1]/div/div[1]/a"))))
#output
<selenium.webdriver.remote.webelement.WebElement (session="73c217a1d58d6ed4483cd09dcbdf6b2e", element="D1AF39C6A3206DADDBDB49059FCD123A_element_12")>
既然都講到了動態爬蟲,那就一定要講到的,向網站傳送資號
訊號分為三種,點擊文字與按鍵
以下範例以"台灣自來水公司搜尋桃園市上田里"作為演示
搜尋結果以2023/8/2的結果為主
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get('https://www.water.gov.tw/wateroff/city/%E6%A1%83%E5%9C%92%E5%B8%82/index.html')
#等待網頁載入完成
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, "/html/body/main/div/div[1]/div[2]/div[1]/select/option[3]")))
#click
driver.find_element(By.XPATH, "/html/body/main/div/div[1]/div[2]/div[1]/select/option[3]").click()
#send_text
driver.find_element(By.CLASS_NAME, "text-input").send_keys("上田里")
#send_keys
driver.find_element(By.CLASS_NAME, "text-input").send_keys(Keys.ENTER)
結果如下
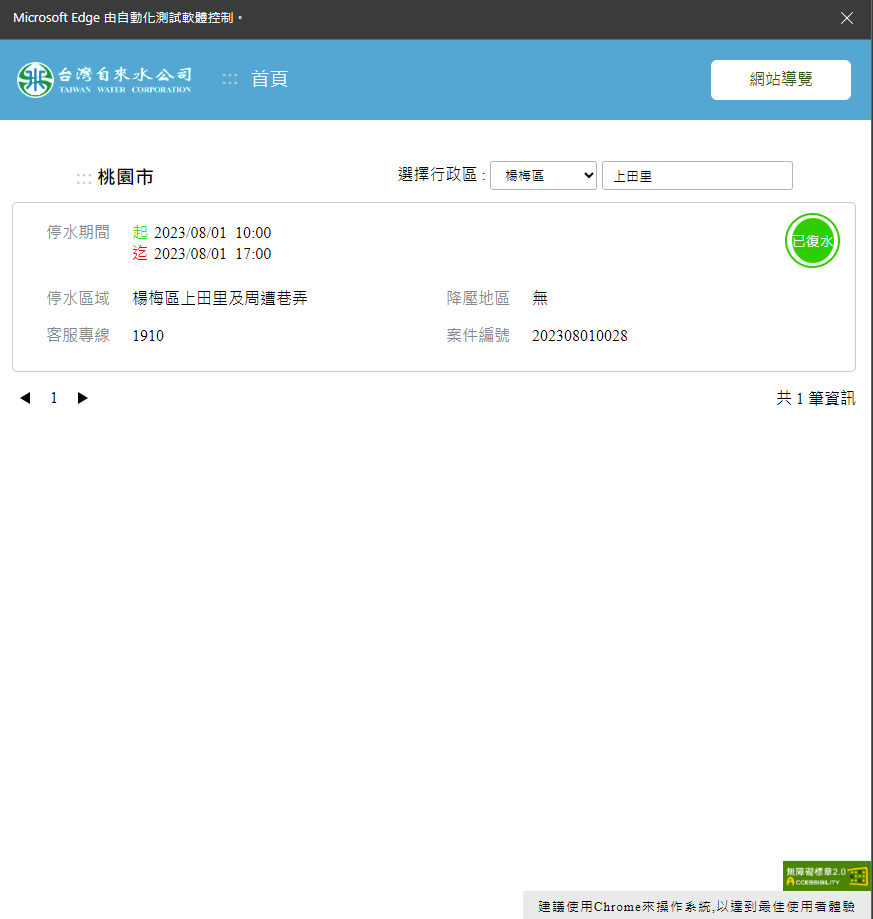
利用絕對路徑去搜尋網頁元素位置,再使用點擊、傳送文字等等的功能,去達成動態爬蟲。
https://selenium-python.readthedocs.io/locating-elements.html
https://www.guru99.com/locate-by-link-text-partial-link-text.
如果碰到那種要登入了,例如蝦皮...
理論上可以 但假如說有開二步驟驗證等等的就會遇到一些麻煩
可以先嘗試看看帶cookie進去
可以參考我DAY 24的文章 裡面有提到如何帶cookie進去


 iThome鐵人賽
iThome鐵人賽